

Why OpenAI’s o3-mini is now Ranking Poorly in the Chatbot Arena? – 11th
OpenAI’s o3-mini was considered the world’s best Reasoning AI Chatbot. Its Reasoning capabilities were considered the best on several benchmarks. Arguably, Grok-3, since its release just a few days ago is now taking the top spot, and for good reasons.
But things seem to be taking a rather different turn in terms of public perception as more people are now using the Chatbot Arena as a yardstick for ranking the different LLMs.
o3-mini Ranks in the Chatbot Arena
The Chatbot Arena is a platform, much more like a competition for AI Chatbots where you can blind-test two anonymous AI chatbots at once. You vote on which one of them has a better answer and then the platform ranks the different AI Chatbots. (“A/B testing” for AI chatbots).
The results thus serve as a real-time benchmark of how different AI models perform based on real user feedback.
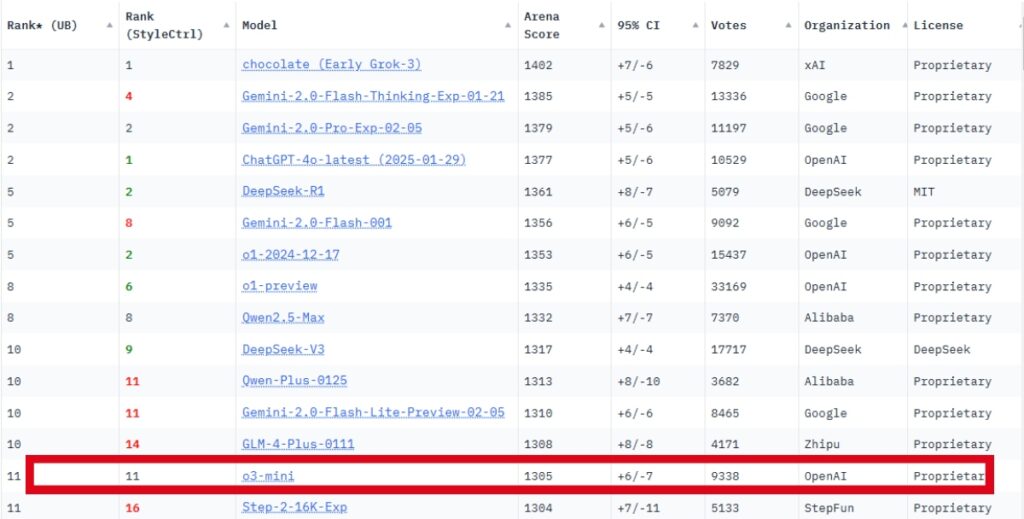
The o3-mini, despite its impressive results in other benchmarks, is ranking 11th in the Arena. With a ranking score of 1305. Even worse than Google’s Gemini -2.
I use o3-mini and I think this may not be a true indication of how good the model is, in comparison to other models. One thing for sure is that it is excellent for STEM tasks (Science, Technology, Engineering, and Maths).
So, if you are trying to use the model for non-STEM tasks, such as basic writing tasks, the results you will get will likely not be the best answers you are looking for.
If you consider the Arena as your yardstick for assessing AI Chatbots, you might be missing the whole point. The platform measures users’ preferences, not necessarily the best models. Also, different AI Chatbots have their strengths and weaknesses.
I think this Reddit user (LazloStPierre) sums it up perfectly;
“Chatbot arena has ceased to be useful as a benchmark to show you which model is smartest or most capable, the average user
1) isn’t asking questions that will test that and
2) isn’t going to know how to differentiate models on the use cases where this will show up, since the general intelligence level has been raised so much”
What is o3-mini Good at?
o3-mini does exclusively well at STEM tasks. Its performance on coding-related tasks is probably the best in the market (some will argue). If however, you are looking for solutions like creative writing, it may not serve you well.
Even OpenAI’s GPT 4o doesn’t seem to offer a better performance on STEM tasks than o3-mini. STEM tasks are its strength.
From a marketing perspective, I think OpenAI is fixing this problem. Sam Altmans revealed during the releasing its roadmap for GPT-4.5 and 5. They will henceforth will only ship an All-in-one model. One that combines all independent models that are good only at specific tasks. So we will expect GPT-4.5 and 5 to do better at the Chatbot Arena.
See: OpenAI Finally Reveals GPT-4.5 & 5 Official Roadmap. What to Expect





